MCP vs. RAG: How AI models access and act on external data
Published on December 3, 2025


Inspiration for your inbox
Subscribe and stay up-to-date on best practices for delivering modern digital experiences.
The recent explosion in the capabilities of AI has led to a modern-day gold rush. Organizations are eager to capitalize on the added value AI can bring to their products. However, many teams fall into the trap of complex, expensive integrations that fail to create an impact.
This raises an important series of questions: How can you connect AI (more specifically, LLMs) to your external data sources in a straightforward way, give it the right context or control, and create something that adds value?
Depending on your use case, there are two main approaches. RAG is designed to work with unstructured data and provide more context to improve an LLM’s response, while MCP servers give LLMs access to systems to perform actions, retrieve data, and provide information.
Here, we’ll discuss MCP vs. RAG, when to use each, and how they’re likely to evolve in the future.
What is RAG?
Retrieval-augmented generation (RAG) improves an LLM’s responses by retrieving relevant external information (normally stable data that rarely changes) and injecting it into the user’s prompt to be used as additional context by the LLM. It’s especially effective for unstructured data, but it can work with any knowledge source that’s either too large to fit in the model’s context or too dynamic to hard-code into the model weights. If you want to work with structured data, converting it into descriptive text requires an extra step.
In theory, RAG allows you to provide the LLM with access to any data source, such as CMSes, product documentation, document stores (e.g., PDFs, Word docs), customer data, or company profiles. The LLM then uses this injected context to provide more accurate answers to your queries. You can think of RAG as a way to provide additional context from your external data without having to retrain the LLM every time that data changes.
How does RAG work?
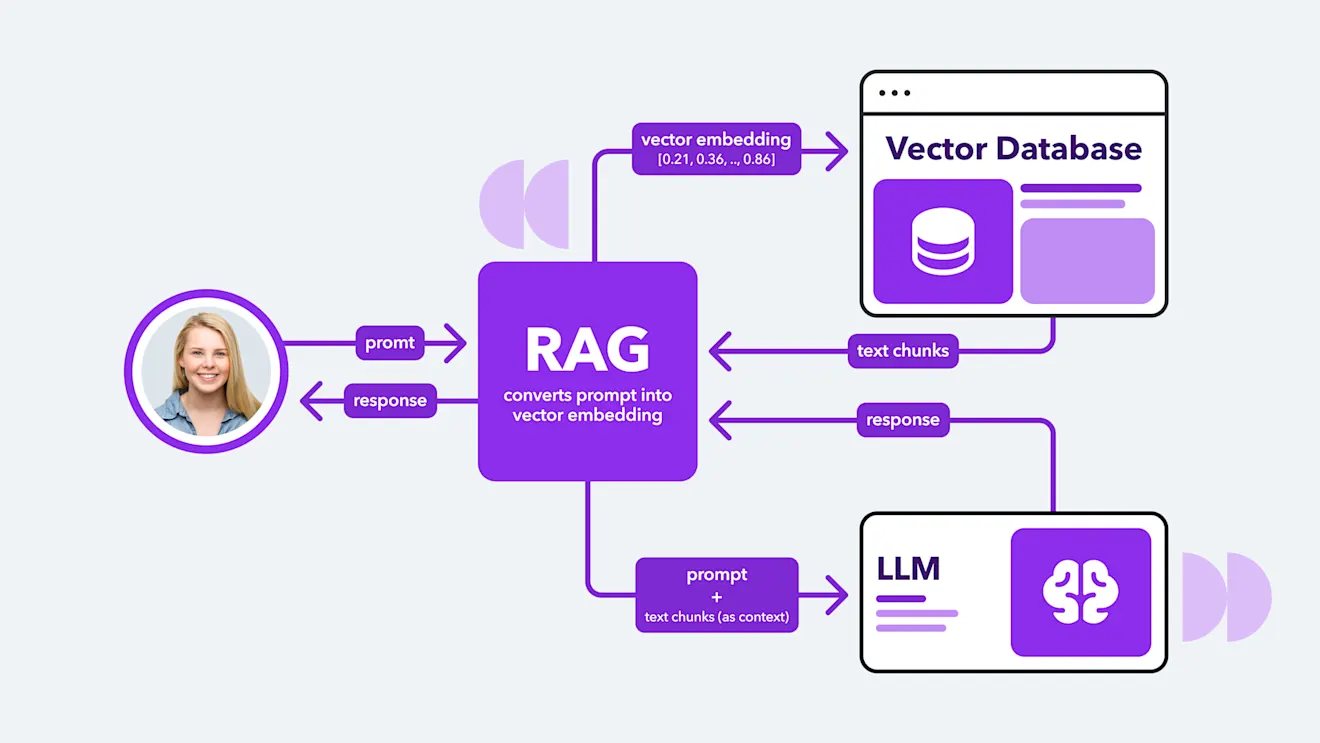
RAG doesn’t allow you to plug straight into live data. You have to process the data ahead of time and store it in a vector database — a specialized database that represents data as numerical vectors and uses similarity search algorithms to find semantically related content. The following are the typical steps to set up a RAG system.
Retrieve the data you need (from the CMS/document store), chunk data, and save each chunk as a vector embedding in a vector database.
When a user asks a question or provides a query, the query is also converted into a vector embedding, so it can be mathematically compared with the existing embeddings in the vector database (previously saved from CMS/document store) as a way to find the data that’s most semantically similar. The most similar embeddings will be returned as their original chunks of data.
These retrieved chunks of data are combined with the original query to create an “augmented prompt.” This prompt is then sent to the LLM.
The LLM then has access to the context from the retrieved documents to generate a more accurate answer.
What is MCP?
Model Context Protocol (MCP) is a standardized protocol for connecting any LLM directly to an external data source in a structured way. It’s designed for structured, action-oriented commands, allowing LLMs to read data and perform actions within your external systems.
With MCP, LLMs can retrieve data from external systems, including databases, APIs, and filesystems, with natural language prompts. It also helps LLMs perform actions such as creating tickets in project management software or batch updating records to save time.
One example of an MCP server you can connect to is the Contentful MCP server.
You could prompt an LLM connected to the server with something like: “Find me all my blog posts that have a status of ‘draft’ and haven’t been updated in the past 30 days.” Then you can use the LLM to do some kind of analysis, such as: “How complete are these articles? Are they on topic with the current trends we’re trying to write about? Are they well written or duplicates of other articles?” The LLM could come up with ideas for changes, like optimizing the content for various LLMs. It could then apply some of those actions to the draft by calling the Contentful MCP server and tagging them with “ready for human review.”
How does MCP work?
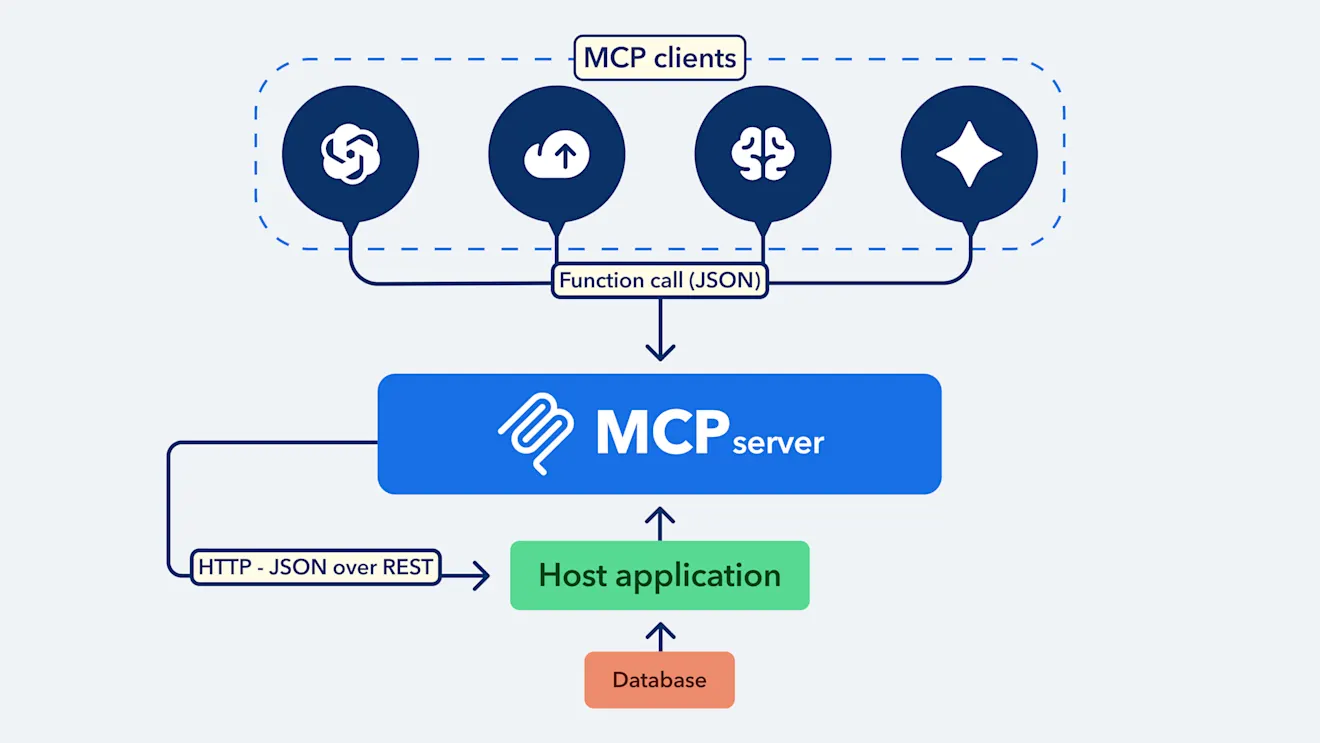
Organizations can build MCP servers that describe how LLMs can interact with their API and database using MCP’s standardized commands, then make their MCP servers discoverable.
MCP-compatible LLM clients (chat interfaces like ChatGPT and Copilot or agent frameworks like LangChain, CrewAI, or AutoGen) can then access these MCP servers to perform actions or retrieve information from the host application. Essentially, it enables your LLM to get real-time, up-to-date data from third-party systems and then act on it if needed.
MCP is typically made up of four components:
Host application: This is the external system providing access to its data and functional capabilities (for example, a CMS or project management software).
MCP server: This is the layer that sits on top of the host application. It defines the functions and tools the LLM can use and connects directly to the API of the host application.
Transport layer: This is normally HTTP and serves as the standard protocol for sending and receiving requests and responses to and from the MCP server.
MCP client: This is the component that allows an AI model to interact with the host application through the MCP server.
MCP vs. RAG comparison: How do they differ?
The main difference between MCP and RAG is that MCP can be used for retrieving data or performing actions, whereas RAG is only for retrieving data. However, if you were to use MCP to retrieve data without performing an action, while it might seem similar at first, it’s still not the same thing as RAG. This is because they are using fundamentally different types of data for different purposes:
RAG retrieves relevant snippets of unstructured text to give the LLM extra memory/context to help it reason better.
MCP retrieves structured, real-time data, typically user-specific or application-specific. It can use this data to perform actions on behalf of those users or on the application’s content.
RAG tends to be for fairly stable data, like a legal policy that doesn’t change too often. Another example of stable data being put to good use is a company that has vectorized its HR policy and company information, allowing new hires to allay any doubts they might have through a chat interface.
Highly dynamic data (such as stock or weather commentary) wouldn’t be optimal in RAG because this kind of data changes too often. The embeddings would need to be updated each time it changes, which is inefficient and prohibitively expensive. In these cases, it’s better to use MCP because it can retrieve real-time structured data and even act on it if needed.
With MCP, you don’t need to vectorize the data since MCP works with structured data. (With RAG, you’re only vectorizing the data so that you can compare the semantic similarity of unstructured data.) MCP is used to connect to external systems to access live data and perform actions based on natural language prompts. For instance, you might ask it to connect to your Google calendar and find out when you’re free next week. You could then have it perform an action like booking a meeting.
The following table illustrates the differences between each method:
Retrieval-augmented generation (RAG) | Model Context Protocol (MCP) | |
|---|---|---|
Purpose | Retrieves relevant unstructured data to enhance an LLM’s response | Provides a standardized way for LLM clients to access structured data or perform actions in external systems |
Can it take action? | No — it’s read-only | Yes — the LLM client can read data, reason about it, and then perform actions |
Type of data it deals with | Unstructured data | Structured data |
Best for | Question answering, analyzing large collections of data (e.g., documents, articles, transcripts) | Tool use: allows LLM clients to act on or retrieve structured data in live systems (e.g., CMSes, CRMs, analytics platforms) |
Security and compliance
With RAG, the fact that you have to store data in a vector database could pose data compliance problems in regulated industries. Unstructured data can contain large amounts of PII or sensitive data, in any form, and with no predictable structure — for example, in patient medical notes or customer support emails.
If your RAG system processes unstructured data that contains personally identifiable information, you still need to ensure your data is anonymized properly, and you must follow industry standards for storage compliance (GDPR). This typically involves using NLP models that have been trained to detect (and then redact) PII, such as Microsoft Presidio, AWS Comprehend, or Google Cloud DLP.
With MCP, the main issue has to do with permission and trust. Because MCP enables AI to perform actions on behalf of a human, a compromised or poorly configured MCP server could become a security issue. For example, there is the risk of poisoned tool definitions, where the LLM agent can be tricked into performing unintended actions.
You can mitigate this by making sure you trust the MCP server you’re connecting to. Check if the server is hosted on the correct domain, and if you’re still unsure, run the server in a staging sandbox environment first to test it. Make sure to keep an audit log and monitor for anything suspicious. It’s also good practice, whenever possible, to check the server’s code or configuration to verify the integrity of its tool definitions.
MCP also has OAuth baked in. It’s a requirement to use it — you can’t just use API keys. Because you are letting an agent perform actions, make sure to only give narrowly scoped permissions (least privilege) and build in human review for sensitive actions, such as publishing a blog post that an AI made changes to.
When to use MCP vs. RAG
RAG is mainly used for question answering over large bodies of unstructured data. However, you can adapt it for semi-structured data. For instance, a database is structured data, but the documentation about it isn’t. So, you could vectorize the schema or documentation of your company’s database and then ask it questions, such as: “Can you tell me more about this database and the different tables in it?” The LLM could then help you understand your company’s data model in a fraction of the time it would have taken otherwise.
MCP is for real-time tasks with structured, up-to-date data, allowing you to interact with external systems. It helps with the repetitive, time-consuming tasks that may slow teams down, like creating dozens of repetitive tickets in project management software.
The two are not mutually exclusive. In fact, you can use them together: For instance, RAG can be used to pull contextualized information about how a system works from its documentation, and MCP can use that context to perform actions on live data in the system.
Real-world example of RAG and MCP being used together
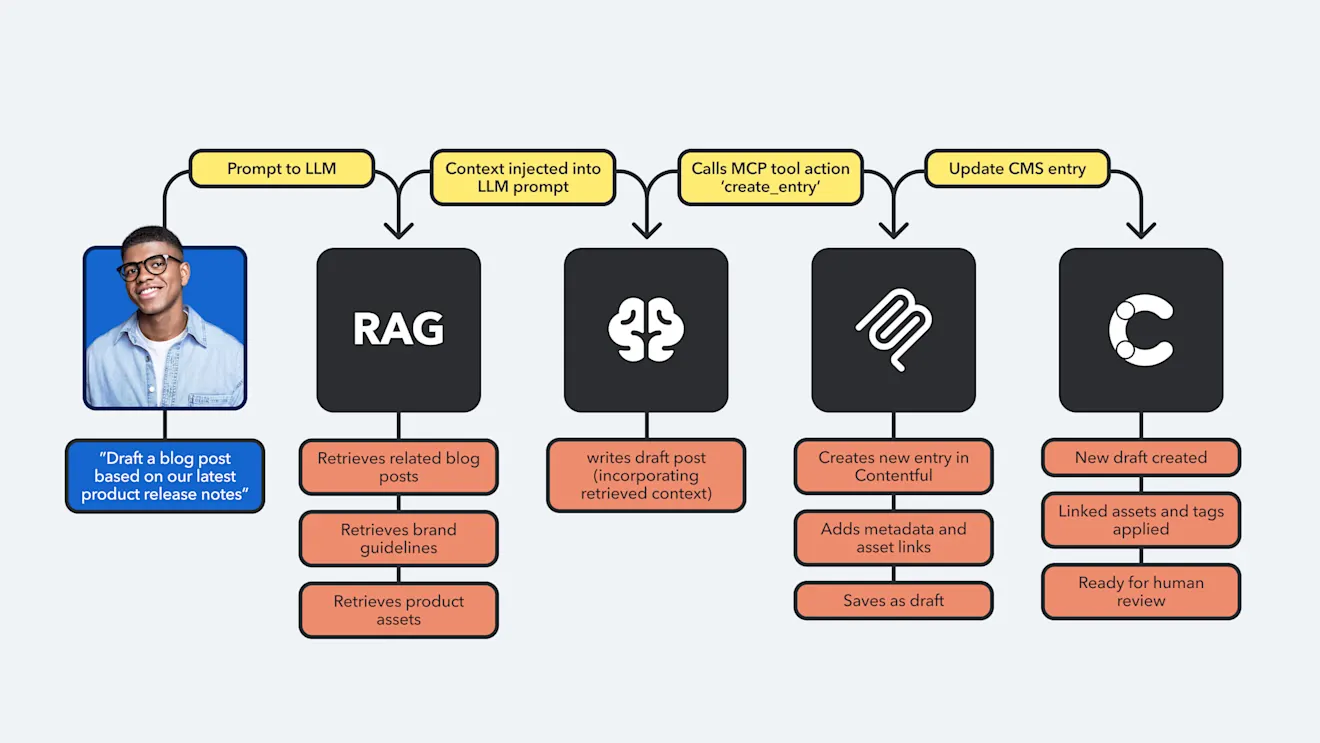
Let’s look at an example of how a Contentful feature that uses RAG under the hood can work alongside the Contentful MCP server to understand how the two can complement each other.
Our content semantics feature, which is available via API as part of our new set of AI features, uses RAG to understand your content at a semantic level. It can detect duplicate entries and suggest existing content that would be good for reuse when you’re creating a new entry. It has access to your whole body of content, allowing it to surface semantically similar entries and suggest existing assets that match your current context.
You can use this feature without having to implement RAG or understand vector databases yourself.
Once that semantic context has been made available, you can hook it into an agent that uses the Contentful MCP server to take an action, such as creating a new blog post or flagging duplicates for review. This is a natural convergence of RAG + MCP on the Contentful platform.
The future of RAG and MCP with AI agents
RAG will likely expand beyond text to include images, audio, and video to allow LLMs to pull richer, multimodal content. As part of this evolution, RAG systems may also become more dynamic, automatically re-indexing content as data changes to keep knowledge up to date.
In theory, it would also be possible to extend a RAG setup by connecting an LLM to an MCP server to query real-time data and feed that live, up-to-date context into prompts to go beyond the static context that RAG retrieval currently offers.
As for how MCP will be used in the near future, it seems to be moving in the direction of AI agents helping to string multiple actions together. You might retrieve some blog posts with an LLM connected to an MCP server, then connect to an SEO tool (through MCP) to retrieve performance metrics on those blog posts. Once it has this information, it could connect to a database of image URLs and select images that go with each article. Then, it could update each article based on the performance metrics and re-post them, all through a single natural language prompt.
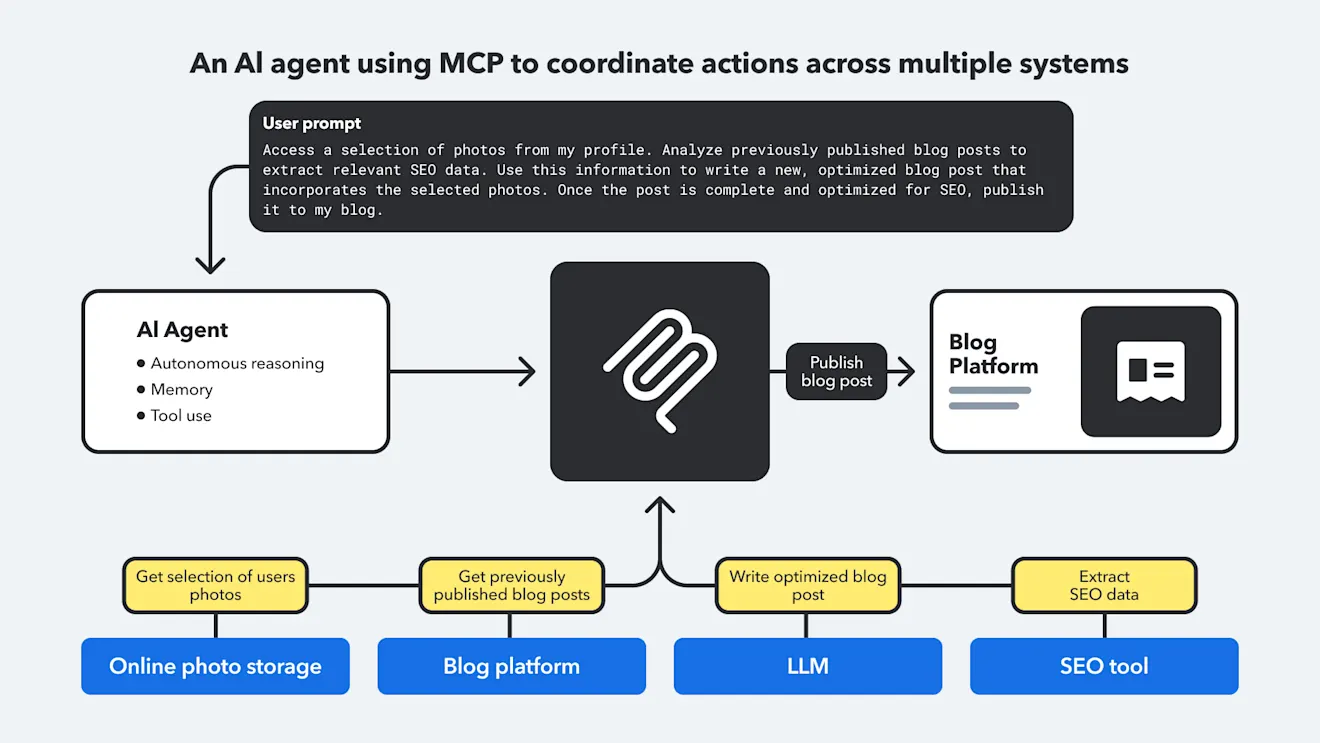
Observability and governance will become even more important as agents become more autonomous. Logs and human insight are already essential for traceability, auditing, and validation, and their scope will expand to handle more complex decision-making. Autonomy shouldn’t remove humans from the loop but rather redefine their role from direct control to supervision.
The Contentful MCP server accelerates your content workflow
The Contentful MCP server is open source and transparent, so you can inspect all of the logic: authentication, API calls, error handling, and tool definitions. It’s also customizable, so it allows developers to modify and extend how it interacts with the Contentful API, although any customizations still operate within the limits of the Contentful API and platform permissions.
You can use natural language prompts to instruct AI agents to:
Manage entries and assets (create, update, publish, unpublish).
Explore and update content types.
Automate operational tasks like tagging, environment management, and migrations.
Create content, run bulk updates, or run SEO checks.
If you’d like to get started with the Contentful MCP server, the steps are straightforward: Install the server from the GitHub repo, connect your LLM, create a Contentful account, authenticate with your Contentful personal access token, and then simply test some prompts out.

Inspiration for your inbox
Subscribe and stay up-to-date on best practices for delivering modern digital experiences.
Meet the authors

Niko is a product manager of developer experience at Contentful. Also, an MCP enthusiast.
Related articles

Building an app? These are the best JavaScript frameworks in 2025
January 30, 2025
Understanding AI by its building blocks: An interactive breakdown of a prompt
February 26, 2026

What is Nuxt? The full-stack framework built on Vue.js
September 26, 2025
