Content modeling basics
Upon logging into Contentful for the first time and creating your first space, you will be prompted to set up your content model. You might be thinking, “My content—what?” If you’re new to Contentful you might not be familiar with the world of content modeling.
A solid content model is the foundation of every great digital project. Your model is the bones of your project; it tells our APIs what kind of content to send to your end application.
In this guide we will go over the principles of content modeling and how to set up your model with Contentful. By the end you will be able to confidently begin your Contentful journey!
The basics
In short, a content model gives structure and organization to your content. Within your overall content model, you’ll have individual content types. You can think of each content type as an outline for your content; it tells you what data will be contained within each individual entry. You can also think of the content type as the “stencil” for the “drawing” that will be your entry.
Each content type is made up of fields that denote the type of data that will be included in the entry. For example, the title of a web page or news article would have its own text field, the body would have another, and there would also be fields to include any media files. This is how you take your website or app from—as our friend Karen McGrane puts it—a big “blob” of content to modular “chunks” or structured content.
Designing your content model is a critical step in building a solid, efficient, and future-proof application with Contentful. The goal is to create a model that will support the needs of your entire team, from the content creators to designers to developers. This is why we always recommend having a session with each team to find out what they need from our composable content platform, and structuring your content accordingly.
Getting into the mindset
Before you begin crafting your Contentful content model, you should take a deep breath and open your mind. Forget what you know about traditional content management systems that restrict your modeling to predefined content types, and stop thinking of content in terms of individual strings of text. Content modeling in Contentful works a bit differently—we’d say better.
With Contentful, your content doesn’t have to be fit into our model—instead, you make the model fit your pieces of content. You get to define a completely unique content model, either via our web app or our Content Management API, that you tailor to your project. Try to think about content modeling from the perspective of your project’s requirements in terms of both design and function. If your blog needs to display metadata about the posts, make sure to include fields for it. Also, if that post needs a “behind the scenes” function, like the option to be featured, you’ll need to add a field to control that. Keep your mind flexible and make Contentful work for you!
Modeling within Contentful also differs from traditional database architecting. If you’ve ever set up content modeling using a spreadsheet, like Excel or Google Sheets, you probably modeled from child item to parent item. In Contentful, we like to copy Mother Nature and model our content from parent to child. This allows you to take into consideration any appearance requirements early in your modeling process.
Start with the big questions: what does the end application need to do and what information needs to be displayed to our users?
Break it down
With those two questions in mind, you can begin thinking about how to actually structure your content model. As said earlier, your overall model is made up of individual content types. Each content type will represent a single unit or module of content within your end application. But where does one content type end and another begin?
The answer to that question depends on how structured or flexible your content model needs to be. Will your content strategists always be entering the same kinds of data? Or, will it change depending on certain criteria? For predictable content items, like an address book, you can probably use only one content type to hold all of the information. An address book entry will always need a name, email address, phone number, etc.
A designer’s portfolio site, however, might need a more flexible model that can accommodate different types of content. One of your posts might be an image but the next needs to be a video, and each media type requires different metadata. In that case, you’d want to create two separate content types—one for images and one for videos—and link them to your post as needed.
It’s also good to identify reusable content elements. A classic example is an author’s bio. Instead of typing out the author’s name and biography blurb into each article, you can create a reusable chunk of content containing the author’s info that can be used over and over. Content reuse can significantly simplify your content creation workflow.
Putting it all together
Once you have an idea of what your content model will need to achieve, it is time to start building it within Contentful! For the purposes of this guide, we’re going to talk about modeling within our web app. There are options on how you can do that: either visually and collaboratively with our Visual Modeler, or using the interface of the content type editor in the “Content model” tab.
You can, of course, set up your content model programmatically, as well — using the Content Management API.
If you’re brand new to Contentful, it’s a good idea to take a quick look at our 5 minute getting started guide so you’re familiar with our platform’s lingo.
Reiterating the changes
When working on a content model, teams collaborate to make sure it is working for everyone and serves its purpose. Developers design the content model, while editors are its end users. It is important that the content model fits them all — corresponds both to the editors’ needs and to how the frontend application is set up.
To build a content model that is really robust and scalable, a team would reiterate — developers plan and build, while their non-technical colleagues test and provide feedback. With our Visual Modeler, you can draft, visualize, share, and collect feedback on your content model — all within the context of the Contentful web app.
Using spaces wisely
Once you’re inside the web app, you will start by creating the spaces for your content model. Each space represents a separate database of content and contains unique content types, entries, and assets, as well as unique user memberships and API keys. Generally, we advise that you keep all of your content within one space, though there are some situations where using multiple spaces is appropriate. Here are some guidelines for working with spaces:
When to use multiple spaces:
For working with separate projects; e.g. client work or multi-stakeholder projects.
To create a “playground” for testing; e.g. trying out features and settings with mock content when first exploring Contentful.
When NOT to use multiple spaces:
For workflow management; e.g. to restrict publishing permissions.
To create multiple staging environments (the Content Preview API should be used for testing draft content).
Reference field basics
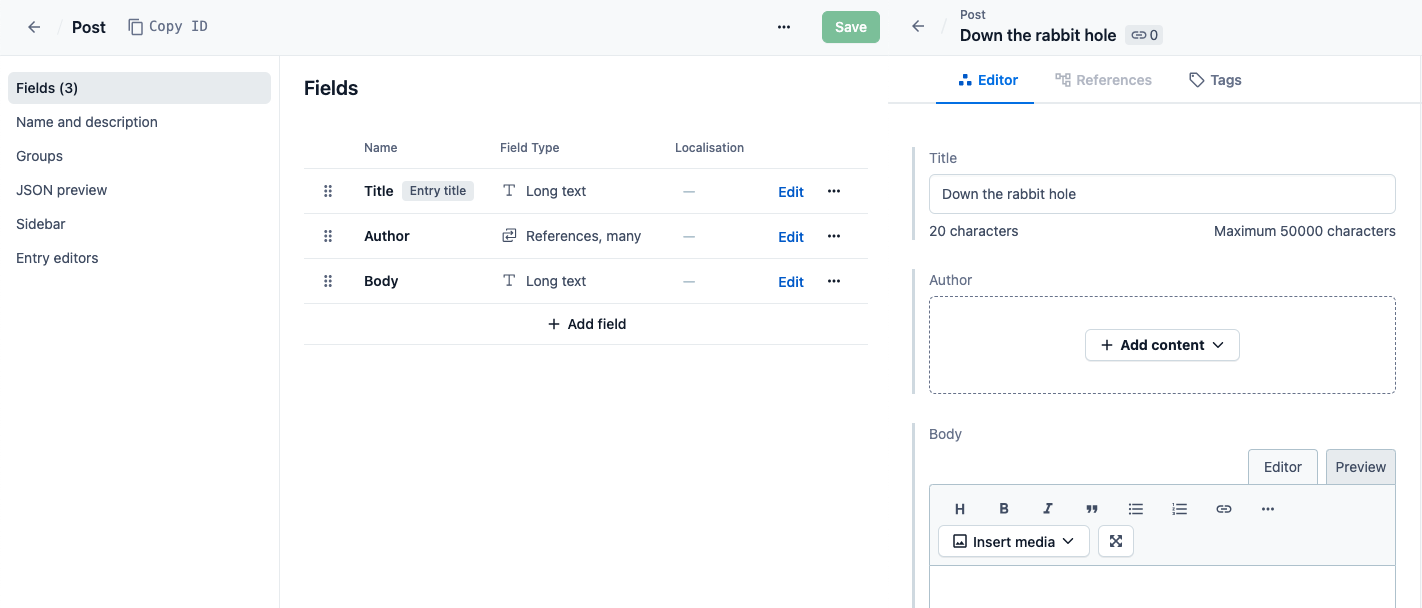
Contentful uses reference fields to create relationships between content types. A basic example of using a reference field is to link a post to its author. You begin by making two content types: one for the post and one for the author. Within the post, you include the necessary fields: a title, a place for the body of the post, and any other metadata. The author content type could include fields for the author’s name, a short bio, and a photo. Once you have both content types set up, all you need to do is re-open the post content type and add a new reference field. Give it a descriptive name like “Author info” and you’re done! Now the post entries will always include a field to link to the author.
Post content type (left) and an entry of that type in the editor (right).
That’s a very simple example of creating a parent-child type of relationship, but reference fields can also be used for far more complex modeling. In our blog post about creating a digital lookbook, we showed how you can use multiple content types and reference fields to create containers to keep your model flexible and modular. Our other blog post about building flexible content models describes a customer that uses reference fields and “container” content types to build a customizable content model for creating landing pages.
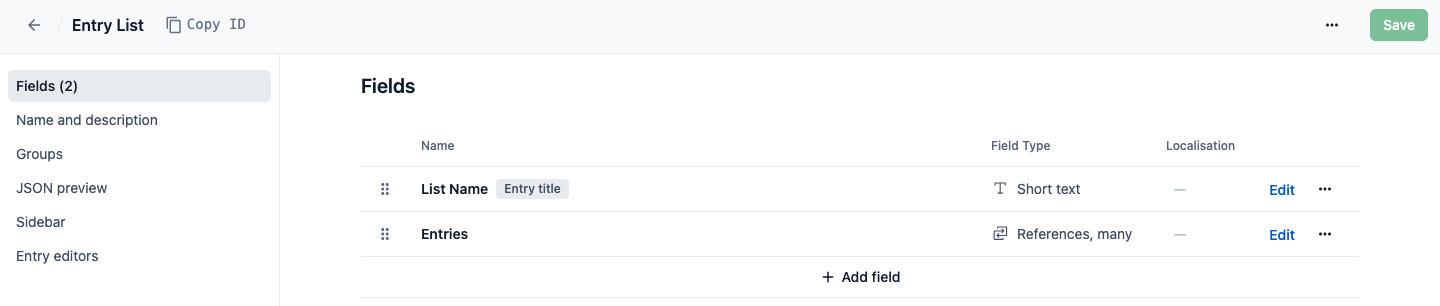
One example of using reference fields creatively is an ordered list of linked content. By first creating a content type to act as a container, you can add a field for linked items that will function as a drag-and-drop list in the entry editor. This works for both reference fields and media fields. Besides the convenience of having an easily sortable list, this also allows you to get all of the referenced content in one API call.
Reference field called "Entries" to make a sortable list.
Always keep in mind that Contentful is designed to be flexible. There are a lot of possibilities based on your content strategy, content ecosystem, and unique content needs. If you don’t immediately see how to model something, don’t give up! Send us a message and we’ll help you figure it out.
Field settings and validations
Each field type comes with a variety of settings you can configure, including appearance and validation options. All of the settings can be modified later with the exception of the field type and ID.
The validations tab
The validations tab in your field’s settings is where you can set specifications and requirements. Need to make sure that the title of your blog post is always 100% filled out? Just mark the field as required and rest easy.
Depending on the field type, there will be other validations you can set like specifying a required number of characters or setting predefined values. One of the useful validations for reference fields lets you specify the content type of the entries that can be referenced. The same goes for the media field — you wouldn’t want to accidentally put a video where an image should be!
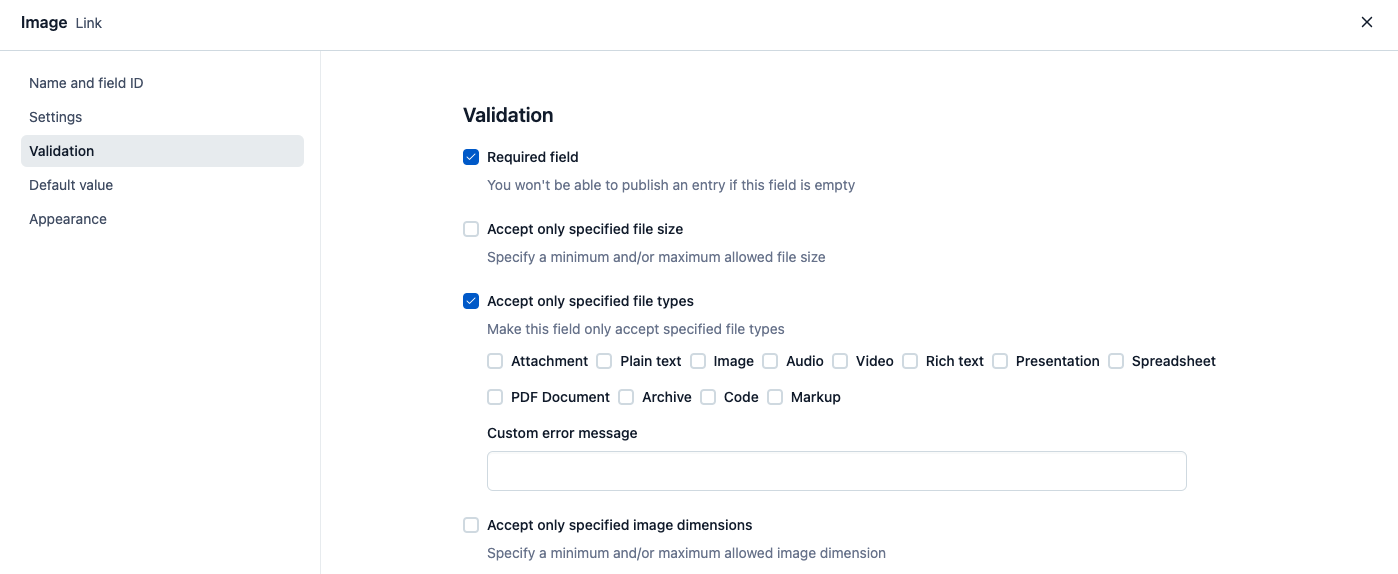
We recommend waiting to add validations until after you have all of your content types set up.
The appearance tab
Navigate to the appearance tab to tell Contentful how you want the field to look within the entry editor. The appearance option that you choose doesn’t affect the way the content shows up in your end application, it simply changes the way it appears within our web app.
Use the appearance options to make the lives of your content creators easier. Instead of having them type into an empty text field, hoping that it matches one of the predefined values, give them a dropdown list so they have a template to choose from. You can also create checkboxes so they can select multiple values.
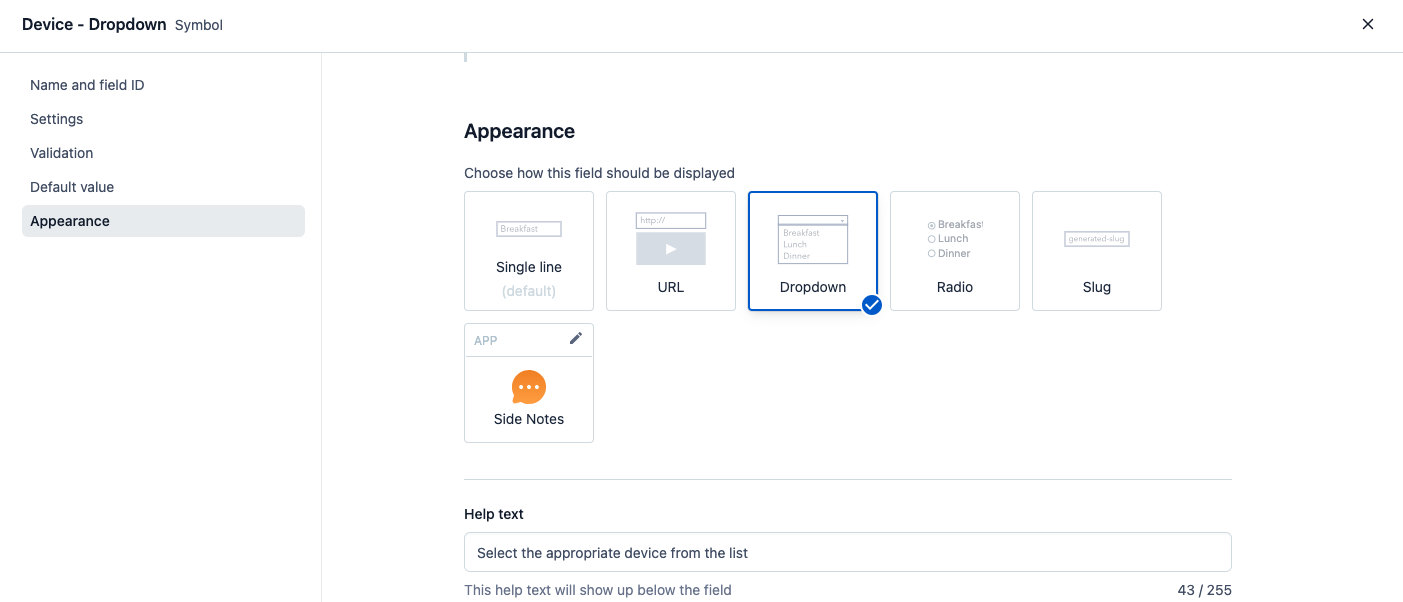
Short text fields.
It is also a good idea to set custom help text to appear under the field to guide your content creators to content marketing success.
Managing your content model
It is highly unlikely that you will set up your content model once and never change it ever again. Luckily, Contentful lets your content model evolve with your project. When the time comes to tweak your model you can edit, disable or delete fields as needed.
Duplicating & deleting content types
If you need to make some changes to a content type but don’t want to mess with your current model, just make a copy! Open your content type within our web app and select ”duplicate” from the actions menu.
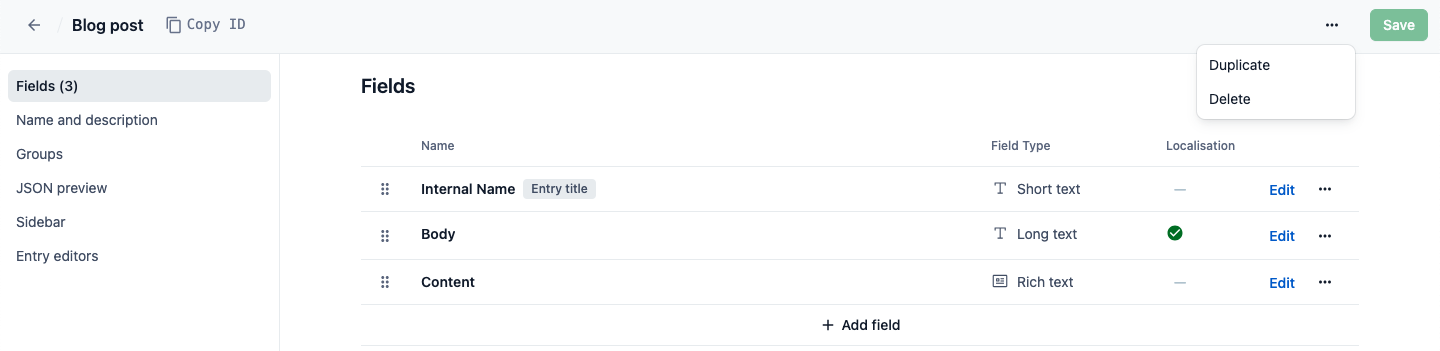
Actions menu within the content type builder.
Once you’re ready to delete the old version of your content type, there are a few steps to follow. First, you must delete all of the entries using the content type. This ensures that you aren’t deleting the content type by accident and that the content in your end application won’t be affected. Without the content type information, how would your application know how the entry is constructed? It can’t and it won’t end well.
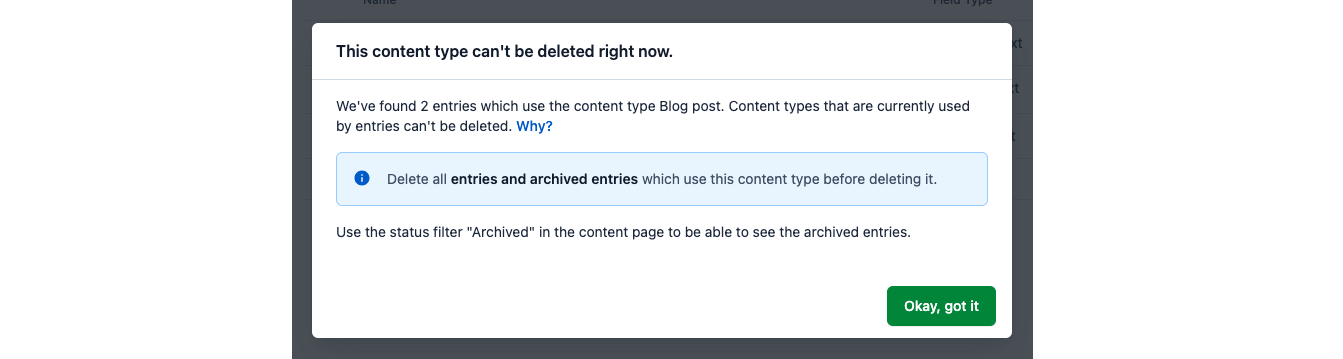
After removing all entries of that content type (including archived items) you can delete the content type completely.
Field management
It’s easy to make small tweaks to your content model, like adding and removing fields. When you add fields to an existing content type, the new field will be automatically added to existing entries. If the new field is required, existing entries won’t be held to the validation until the entry is updated. This means that older entries of that content type will remain published, despite the empty required field, until you make changes to that entry. At that point, you will need to fill out the required field before re-publishing.
Hide fields when editing
Hide field when editing means that a field is hidden in the entry editor, but its content remains present in the API response. Use this status to hide a specific field from the editors.
NOTE: A user still has an option to show a hidden field and edit its content in the entry editor. To restrict a user from editing the hidden field, configure the user's space role accordingly — for example, add a deny rule preventing the user from editing this field.
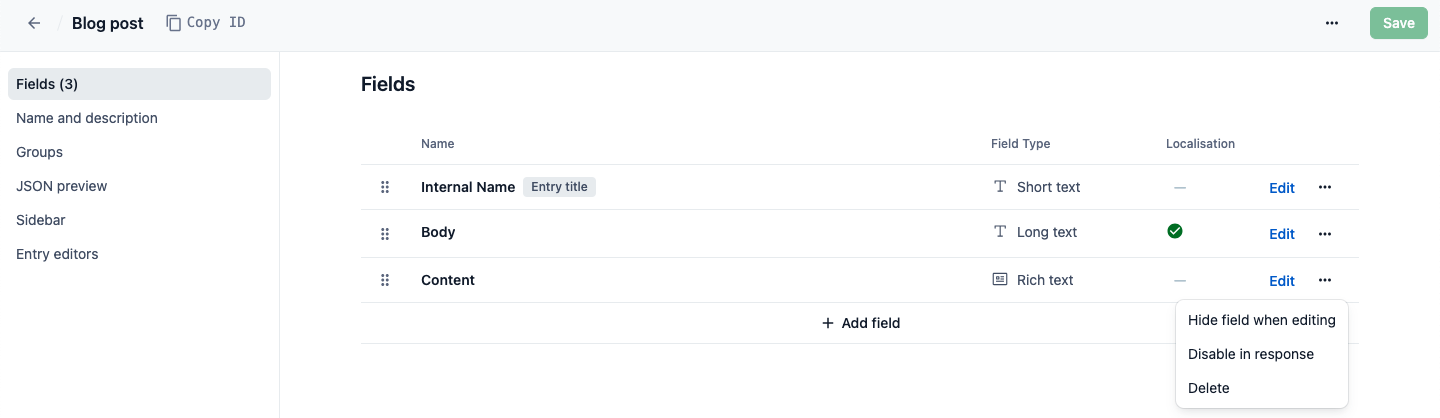
Omit from API response
Omitting fields from the API response means that the content cannot be fetched by the Content Delivery API and the Content Preview API, and thus is not available to your end application. These fields are still editable in the entry editor. One use case would be for fields that are only relevant within the Contentful web app, such as fields that indicate an entry’s status in your workflow. That information does not need to be available in your end application, so why not make things more efficient by leaving it out of the response? We’re all for optimization!
Delete fields
Before deleting a field, you must first disable it in the API response. This two-step process gives you extra protection from mistakenly deleted fields, which could be disastrous for your end app! Also, by first disabling the field in the response, you can preview what your API responses will look like after the field deletion. Always make sure to test your responses before deleting any fields!
Getting support
Content modeling is a broad and sometimes complicated topic so don’t worry if you still feel a bit lost. This guide has only scratched the surface. If you get stuck during your modeling process, don’t hesitate to reach out. You can always send us a chat message or, for more complex questions, send a support request.
Additional resources
Learn more about content modeling with Contentful by taking the training courses in our Learning Center: